
Overview
This page shows a simple, reproducible way to track experiments in Jupyter. Each training run writes to
/workspace/runs/<run_id>/ with a meta.json (hyperparameters, seed, classes),
a streaming metrics.csv (loss/accuracy per epoch), and checkpoints (best.pt, last.pt).
Curves export into /workspace/outputs/plots/ for sharing.
Tip: Name runs with meaningful IDs like
res18_bs32_lr1e-3_seed42. You can quickly compare them later.
Standard layout
/workspace/
runs/
res18_bs32_lr1e-3_seed42/
meta.json
metrics.csv
best.pt
last.pt
smallcnn_bs32_lr1e-3_seed42/
...
outputs/
plots/
curves_res18_bs32_lr1e-3_seed42.png
curves_smallcnn_bs32_lr1e-3_seed42.png
Bootstrap folders
# One-time setup for this page
from pathlib import Path
ROOT = Path("/workspace")
(ROOT/"runs").mkdir(parents=True, exist_ok=True)
(ROOT/"outputs/plots").mkdir(parents=True, exist_ok=True)
print("Ready:", ROOT/"runs", ROOT/"outputs/plots")
Minimal RunLogger
import csv, json, time
from pathlib import Path
class RunLogger:
def __init__(self, run_id, root="/workspace"):
self.root = Path(root)
self.dir = self.root/"runs"/run_id
self.dir.mkdir(parents=True, exist_ok=True)
self.meta_path = self.dir/"meta.json"
self.metrics_path = self.dir/"metrics.csv"
self._init_metrics()
def _init_metrics(self):
if not self.metrics_path.exists():
with open(self.metrics_path, "w", newline="") as f:
csv.writer(f).writerow(["epoch","train_loss","val_loss","train_acc","val_acc","time_sec"])
def save_meta(self, **meta):
meta["created_at"] = time.strftime("%Y-%m-%d %H:%M:%S")
with open(self.meta_path, "w") as f:
json.dump(meta, f, indent=2)
def log_epoch(self, epoch, train_loss, val_loss, train_acc, val_acc, time_sec):
with open(self.metrics_path, "a", newline="") as f:
csv.writer(f).writerow([epoch, train_loss, val_loss, train_acc, val_acc, time_sec])
# Example: create a run
run_id = "smallcnn_bs32_lr1e-3_seed42"
logger = RunLogger(run_id)
logger.save_meta(model="SmallCNN", batch=32, lr=1e-3, seed=42, dataset="clean_imagefolder")
print("Run dir:", logger.dir)
Training loop (hooks to logger)
import torch, torch.nn as nn, torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import math, time, numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Data (same as skeleton page)
DATA = Path("/workspace/data/images/clean")
train_tf = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()])
val_tf = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()])
full = datasets.ImageFolder(DATA, transform=train_tf)
classes = full.classes
val_len = math.ceil(len(full)*0.2)
train_len= len(full)-val_len
train_set, val_set = random_split(full, [train_len, val_len])
val_set.dataset.transform = val_tf
train_loader = DataLoader(train_set, batch_size=32, shuffle=True, num_workers=2, pin_memory=True)
val_loader = DataLoader(val_set, batch_size=32, shuffle=False, num_workers=2, pin_memory=True)
class SmallCNN(nn.Module):
def __init__(self, n):
super().__init__()
self.c1=nn.Conv2d(3,32,3,padding=1); self.c2=nn.Conv2d(32,64,3,padding=1); self.c3=nn.Conv2d(64,128,3,padding=1)
self.pool=nn.MaxPool2d(2,2); self.head=nn.Linear(128,n)
def forward(self,x):
x=self.pool(F.relu(self.c1(x))); x=self.pool(F.relu(self.c2(x))); x=self.pool(F.relu(self.c3(x)))
x=F.adaptive_avg_pool2d(x,(1,1)).flatten(1); return self.head(x)
model = SmallCNN(len(classes)).to(device)
opt = torch.optim.AdamW(model.parameters(), lr=1e-3)
best_acc=0.0
CKPT_BEST = logger.dir/"best.pt"
CKPT_LAST = logger.dir/"last.pt"
def run_epoch(loader, train=True):
model.train(mode=train)
tot=0; ok=0; loss_sum=0.0
for x,y in loader:
x,y=x.to(device), y.to(device)
with torch.set_grad_enabled(train):
out = model(x)
loss= F.cross_entropy(out, y)
if train: opt.zero_grad(set_to_none=True); loss.backward(); opt.step()
loss_sum += loss.item()*x.size(0)
ok += (out.argmax(1)==y).sum().item()
tot+= x.size(0)
return loss_sum/tot, ok/tot
EPOCHS=8
for ep in range(1,EPOCHS+1):
t0=time.time()
tr_loss,tr_acc=run_epoch(train_loader, True)
va_loss,va_acc=run_epoch(val_loader, False)
dt=time.time()-t0
# stream log
logger.log_epoch(ep, tr_loss, va_loss, tr_acc, va_acc, dt)
# save last/best
torch.save({"model":model.state_dict(),"classes":classes,"epoch":ep},
CKPT_LAST)
if va_acc>best_acc:
best_acc=va_acc
torch.save({"model":model.state_dict(),"classes":classes,"epoch":ep},
CKPT_BEST)
print(f"ep{ep:02d} train {tr_loss:.4f}/{tr_acc:.3f} val {va_loss:.4f}/{va_acc:.3f} {dt:.1f}s")
print("Done. Logs:", logger.metrics_path)
Plot curves from metrics.csv
import pandas as pd, matplotlib.pyplot as plt
PLOTS = Path("/workspace/outputs/plots"); PLOTS.mkdir(parents=True, exist_ok=True)
def plot_curves(metrics_csv, title, out_png):
df = pd.read_csv(metrics_csv)
plt.figure()
plt.plot(df["epoch"], df["train_loss"], label="train_loss")
plt.plot(df["epoch"], df["val_loss"], label="val_loss")
plt.xlabel("epoch"); plt.ylabel("loss"); plt.title(title)
plt.grid(True, alpha=.3); plt.legend(); plt.tight_layout()
plt.savefig(out_png); plt.show()
plot_curves(logger.metrics_path, f"Curves — {run_id}", PLOTS/f"curves_{run_id}.png")

Curves exported from /workspace/outputs/plots/ (replace with yours).
Compare multiple runs
import pandas as pd, matplotlib.pyplot as plt
import glob, os
RUNS = Path("/workspace/runs")
def best_val_acc(metrics_csv):
df=pd.read_csv(metrics_csv)
return float(df["val_acc"].max()), len(df)
cands=[]
for metrics_csv in glob.glob(str(RUNS/"*"/"metrics.csv")):
run_name = Path(metrics_csv).parent.name
acc, epochs = best_val_acc(metrics_csv)
cands.append((run_name, acc, epochs))
cands = sorted(cands, key=lambda x: x[1], reverse=True)
for r,a,e in cands:
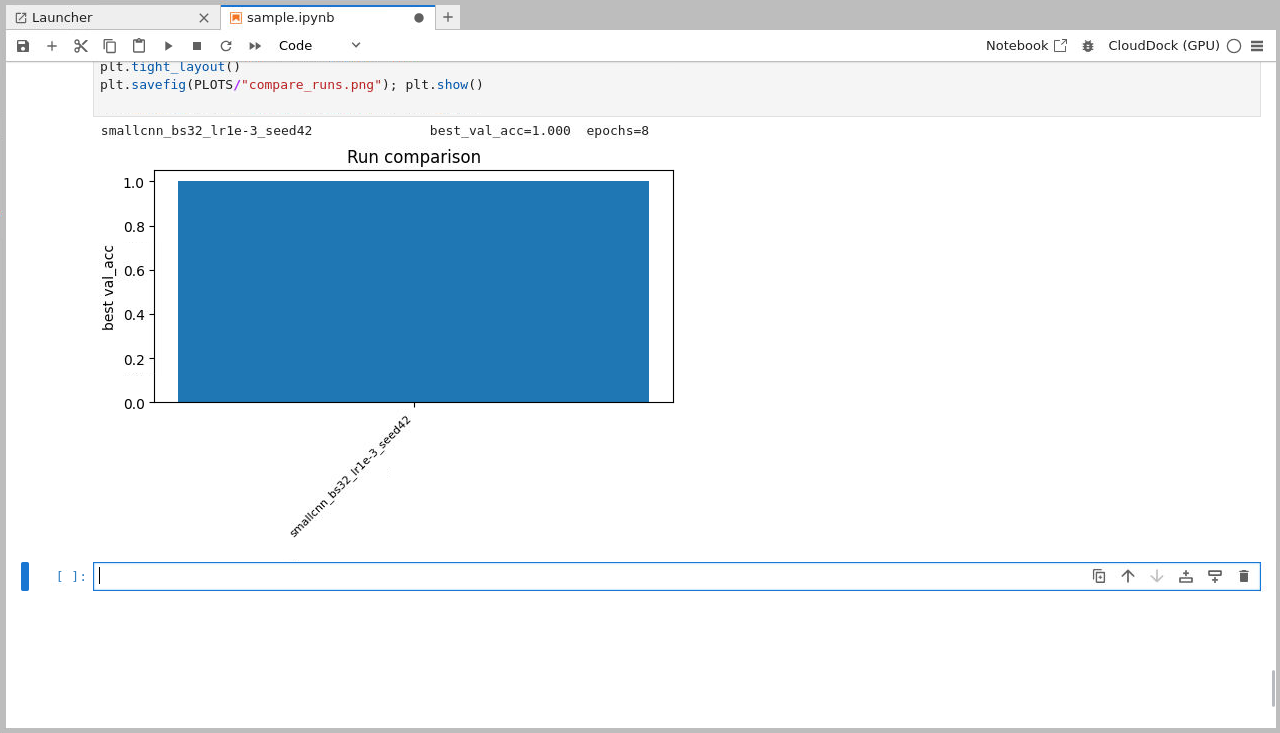
print(f"{r:40s} best_val_acc={a:.3f} epochs={e}")
# bar chart
names=[r for r,_,_ in cands]; accs=[a for _,a,_ in cands]
plt.figure(figsize=(min(12, max(6, len(names)*0.6)), 4.2))
plt.bar(range(len(names)), accs)
plt.xticks(range(len(names)), names, rotation=45, ha="right", fontsize=8)
plt.ylabel("best val_acc"); plt.title("Run comparison")
plt.tight_layout()
plt.savefig(PLOTS/"compare_runs.png"); plt.show()
Housekeeping (rotate old runs)
import shutil
def keep_top_runs(top_k=5, min_acc=0.0):
items=[]
for d in RUNS.iterdir():
m=d/"metrics.csv"
if m.exists():
try:
df=pd.read_csv(m)
items.append((d, float(df["val_acc"].max())))
except: pass
# by acc desc
items.sort(key=lambda x:x[1], reverse=True)
to_keep=[d for d,_ in items[:top_k] if _>=min_acc]
for d,_ in items:
if d not in to_keep:
print("removing:", d)
shutil.rmtree(d, ignore_errors=True)
# keep_top_runs(top_k=5, min_acc=0.0)
FAQ
Where are my plots?
Under /workspace/outputs/plots/. Download them from Jupyter’s file browser and upload to your site if needed.
How do I resume a run?
Load last.pt, restore the optimizer and epoch index, and keep logging into the same metrics.csv (append mode).
Can I push metrics to an external tracker?
Yes, but this page keeps it local for portability. You can mirror logs to your preferred service later.
What gets measured gets improved.