
Overview
This page gives you a drop-in PyTorch skeleton for image classification in Jupyter.
It expects an ImageFolder-style dataset under
/workspace/data/images/clean/<class>/<file>.jpg.
You get a minimal CNN (works offline), training/validation split, checkpoints, curves, and a confusion matrix.
/workspace/data/images/clean/.
Project layout
/workspace/
data/
images/
clean/
class_a/*.jpg
class_b/*.jpg
outputs/
plots/
train_curves.png
confusion_matrix.png
runs/
cls_exp1/
best.pt
last.pt
meta.json
notebooks/
Environment
# Install once per kernel
%pip install torch torchvision scikit-learn matplotlib tqdm --quiet
Optional: bootstrap a toy dataset
If you don’t have a dataset yet, generate a tiny 2-class set (offline) to test the pipeline.
%pip install pillow --quiet
from PIL import Image, ImageDraw
from pathlib import Path
root = Path("/workspace/data/images/clean")
for c in ["circle","square"]:
(root/c).mkdir(parents=True, exist_ok=True)
def circle(p, s=256, color=(60,120,220)):
im = Image.new("RGB",(s,s),(245,245,245))
d = ImageDraw.Draw(im); r=s//3; c=s//2
d.ellipse((c-r,c-r,c+r,c+r), fill=color); im.save(p, quality=92)
def square(p, s=256, color=(220,120,60)):
im = Image.new("RGB",(s,s),(245,245,245))
d = ImageDraw.Draw(im); q=s//3*2; x0=(s-q)//2
d.rectangle((x0,x0,x0+q,x0+q), fill=color); im.save(p, quality=92)
for i in range(120):
circle(root/"circle"/f"c_{i:03d}.jpg")
square(root/"square"/f"s_{i:03d}.jpg")
print("Toy dataset ready under", root)
Dataset & DataLoader
import torch, json, time, math, random
from pathlib import Path
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
# ----- Reproducibility -----
SEED = 42
torch.manual_seed(SEED); random.seed(SEED)
ROOT = Path("/workspace")
DATA = ROOT/"data/images/clean"
RUNS = ROOT/"runs/cls_exp1"; RUNS.mkdir(parents=True, exist_ok=True)
PLOTS = ROOT/"outputs/plots"; PLOTS.mkdir(parents=True, exist_ok=True)
# ----- Transforms -----
train_tf = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
val_tf = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
full = datasets.ImageFolder(DATA, transform=train_tf)
class_names = full.classes
num_classes = len(class_names)
print("Classes:", class_names, "Total images:", len(full))
# Split train/val (80/20)
val_ratio = 0.2
val_len = math.ceil(len(full) * val_ratio)
train_len = len(full) - val_len
train_set, val_set = random_split(full, [train_len, val_len],
generator=torch.Generator().manual_seed(SEED))
# Apply val transforms
val_set.dataset.transform = val_tf
BATCH = 32
train_loader = DataLoader(train_set, batch_size=BATCH, shuffle=True, num_workers=2, pin_memory=True)
val_loader = DataLoader(val_set, batch_size=BATCH, shuffle=False, num_workers=2, pin_memory=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
Model — small CNN (offline)
import torch.nn as nn
import torch.nn.functional as F
class SmallCNN(nn.Module):
def __init__(self, n_classes):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64,128, 3, padding=1)
self.pool = nn.MaxPool2d(2,2)
self.head = nn.Linear(128, n_classes)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 112x112
x = self.pool(F.relu(self.conv2(x))) # 56x56
x = self.pool(F.relu(self.conv3(x))) # 28x28
x = F.adaptive_avg_pool2d(x, (1,1)).squeeze(-1).squeeze(-1)
return self.head(x)
model = SmallCNN(num_classes).to(device)
sum(p.numel() for p in model.parameters())/1e6
Training loop + checkpoints
from tqdm import tqdm
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix
EPOCHS = 8
LR = 1e-3
opt = optim.AdamW(model.parameters(), lr=LR)
best_acc = 0.0
history = {"epoch":[], "train_loss":[], "val_loss":[], "train_acc":[], "val_acc":[]}
def run_epoch(loader, train=True):
model.train(mode=train)
total, correct, loss_sum = 0, 0, 0.0
for x,y in tqdm(loader, leave=False):
x,y = x.to(device), y.to(device)
with torch.set_grad_enabled(train):
logits = model(x)
loss = F.cross_entropy(logits, y)
if train:
opt.zero_grad(set_to_none=True)
loss.backward()
opt.step()
loss_sum += loss.item() * x.size(0)
pred = logits.argmax(1)
correct += (pred==y).sum().item()
total += x.size(0)
return loss_sum/total, correct/total
for epoch in range(1, EPOCHS+1):
t0 = time.time()
tr_loss, tr_acc = run_epoch(train_loader, train=True)
va_loss, va_acc = run_epoch(val_loader, train=False)
history["epoch"].append(epoch)
history["train_loss"].append(tr_loss); history["val_loss"].append(va_loss)
history["train_acc"].append(tr_acc); history["val_acc"].append(va_acc)
# Save last
torch.save({"model":model.state_dict(),
"classes":class_names,
"epoch":epoch,
"history":history},
RUNS/"last.pt")
# Save best
if va_acc > best_acc:
best_acc = va_acc
torch.save({"model":model.state_dict(),
"classes":class_names,
"epoch":epoch,
"history":history},
RUNS/"best.pt")
print(f"Epoch {epoch:02d} "
f"train {tr_loss:.4f}/{tr_acc:.3f} "
f"val {va_loss:.4f}/{va_acc:.3f} "
f"time {(time.time()-t0):.1f}s")
# Persist meta
import json
meta = {"classes": class_names, "epochs": EPOCHS, "batch": BATCH, "lr": LR, "seed": SEED}
json.dump(meta, open(RUNS/"meta.json","w"), indent=2)
print("Saved checkpoints to", RUNS)
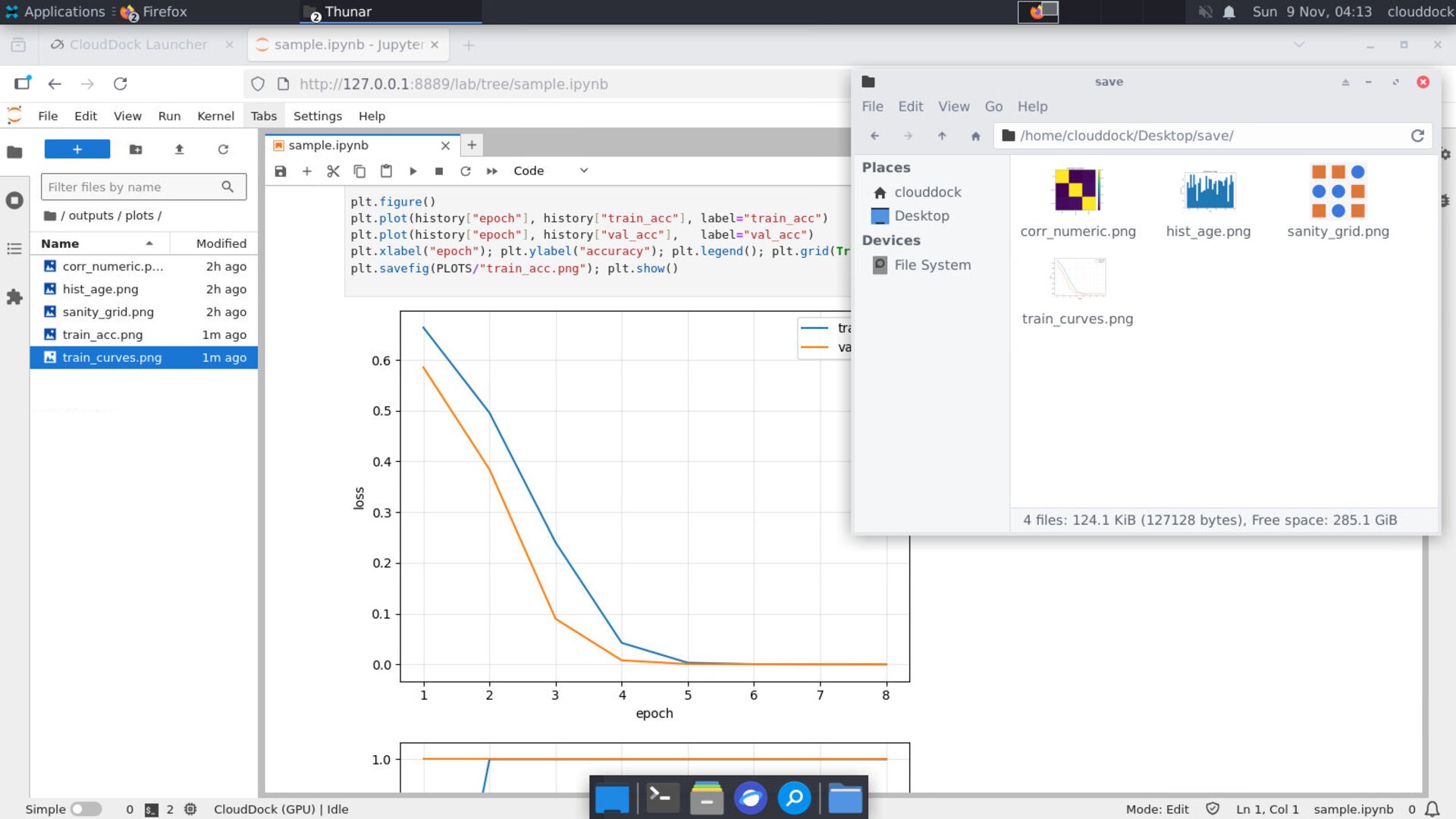
Curves — loss & accuracy
plt.figure()
plt.plot(history["epoch"], history["train_loss"], label="train_loss")
plt.plot(history["epoch"], history["val_loss"], label="val_loss")
plt.xlabel("epoch"); plt.ylabel("loss"); plt.legend(); plt.grid(True, alpha=.3); plt.tight_layout()
plt.savefig(PLOTS/"train_curves.png"); plt.show()
plt.figure()
plt.plot(history["epoch"], history["train_acc"], label="train_acc")
plt.plot(history["epoch"], history["val_acc"], label="val_acc")
plt.xlabel("epoch"); plt.ylabel("accuracy"); plt.legend(); plt.grid(True, alpha=.3); plt.tight_layout()
plt.savefig(PLOTS/"train_acc.png"); plt.show()
Evaluation — confusion matrix
# Collect predictions on val set
y_true, y_pred = [], []
model.eval()
with torch.no_grad():
for x,y in val_loader:
x = x.to(device)
logits = model(x)
y_pred.extend(logits.argmax(1).cpu().tolist())
y_true.extend(y.cpu().tolist())
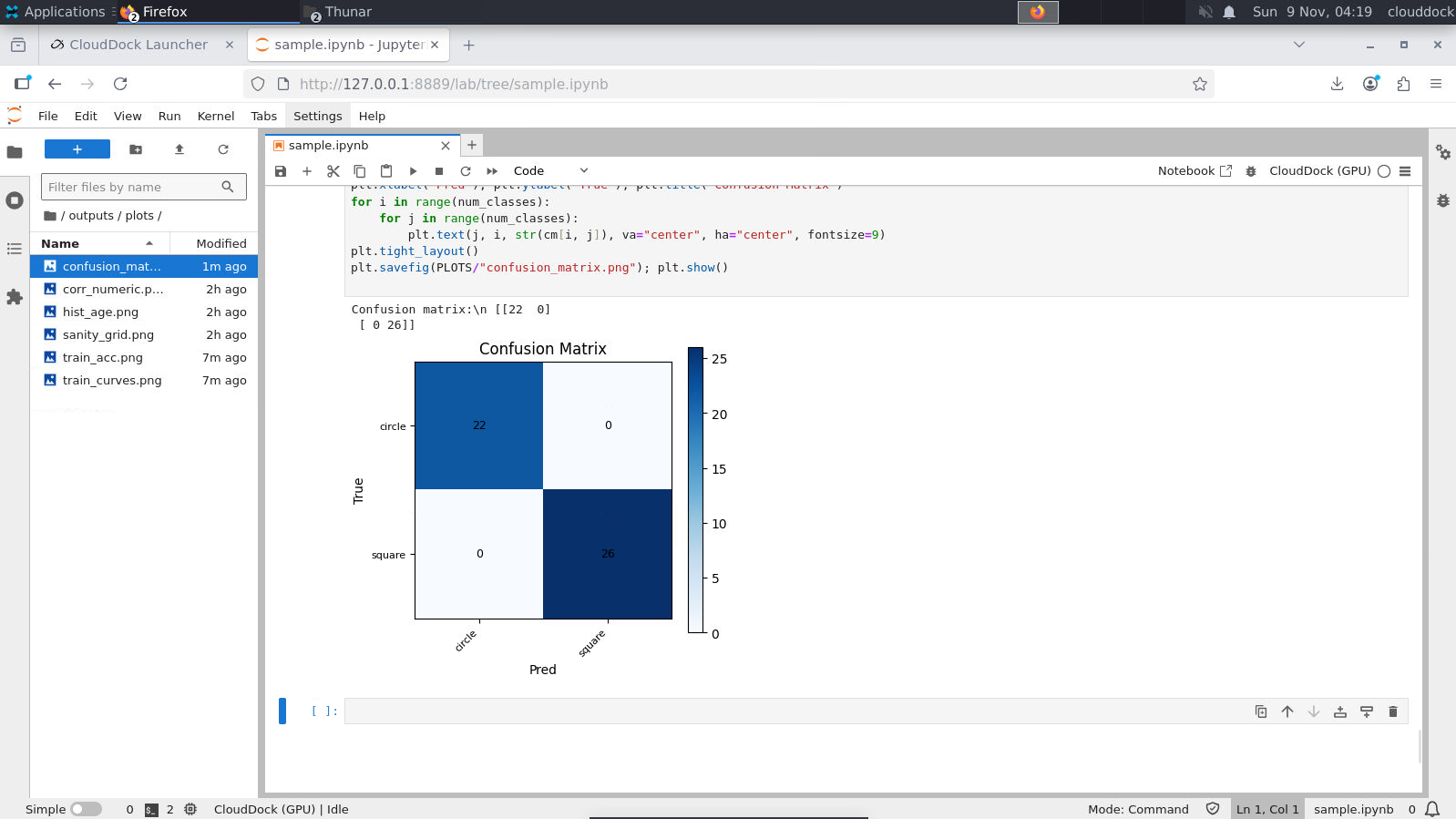
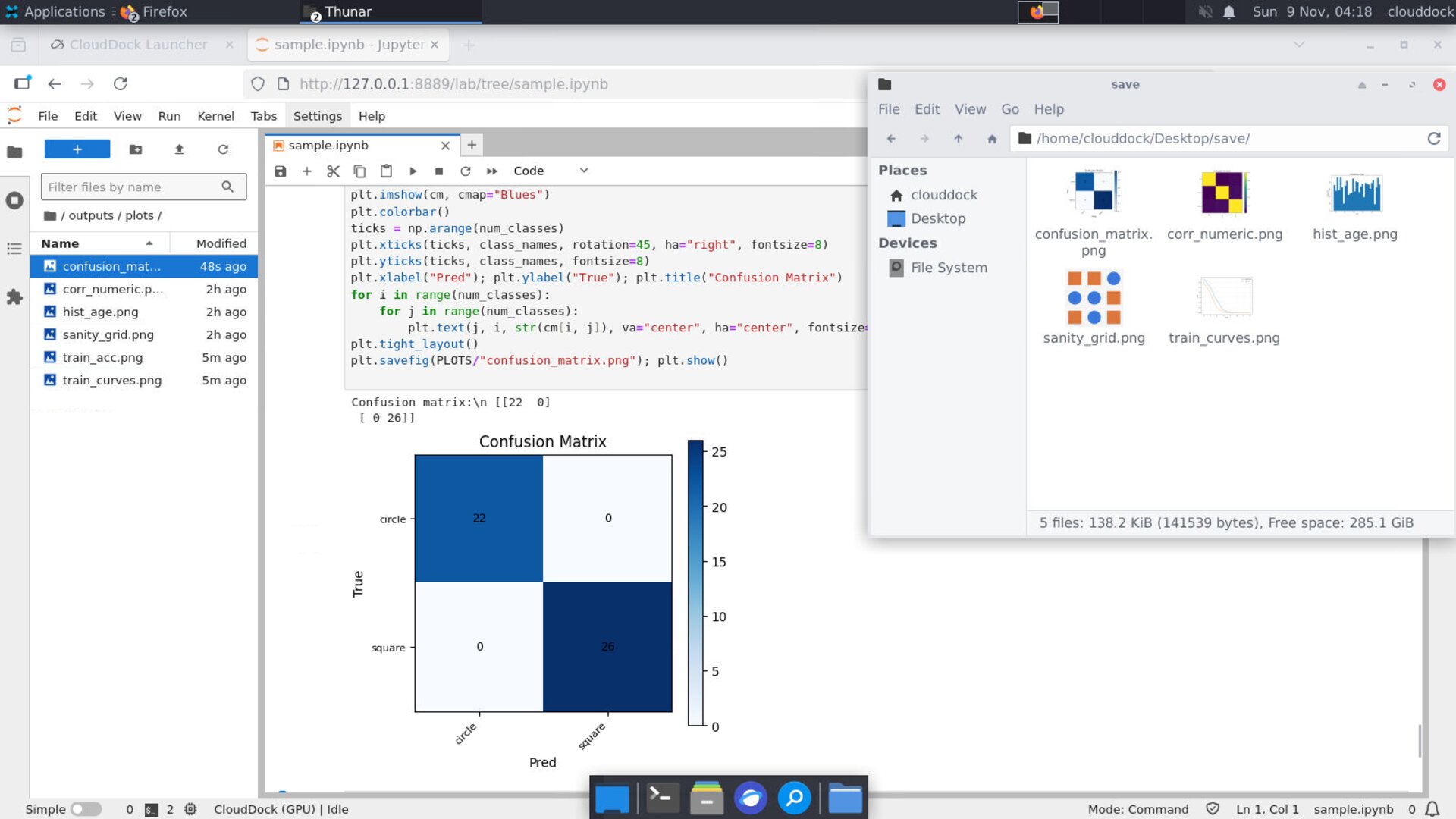
cm = confusion_matrix(y_true, y_pred, labels=list(range(num_classes)))
print("Confusion matrix:\\n", cm)
# Minimal heatmap (no seaborn)
plt.figure(figsize=(4.5,4))
plt.imshow(cm, cmap="Blues")
plt.colorbar()
ticks = np.arange(num_classes)
plt.xticks(ticks, class_names, rotation=45, ha="right", fontsize=8)
plt.yticks(ticks, class_names, fontsize=8)
plt.xlabel("Pred"); plt.ylabel("True"); plt.title("Confusion Matrix")
for i in range(num_classes):
for j in range(num_classes):
plt.text(j, i, str(cm[i, j]), va="center", ha="center", fontsize=9)
plt.tight_layout()
plt.savefig(PLOTS/"confusion_matrix.png"); plt.show()
Resume & inference
# Resume best
ckpt = torch.load(RUNS/"best.pt", map_location=device)
model.load_state_dict(ckpt["model"])
class_names = ckpt["classes"]
# Single image inference
from PIL import Image
infer_tf = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()])
p = next(iter((DATA/class_names[0]).glob("*.jpg"))) # take one
im = Image.open(p).convert("RGB")
x = infer_tf(im).unsqueeze(0).to(device)
with torch.no_grad():
prob = torch.softmax(model(x), dim=1).squeeze(0).cpu().tolist()
pred = class_names[int(np.argmax(prob))]
print("Pred:", pred, "Probs:", dict(zip(class_names, [round(v,3) for v in prob])))
FAQ
GPU runs out of memory
Lower BATCH (e.g., 16 → 8 → 4). You can also resize smaller (e.g., 224 → 160) or switch to CPU temporarily.
Training is too slow
Increase num_workers in DataLoader (try 4 or 8). Ensure your dataset lives on the local disk (inside the container).
Can I use a pretrained model?
Yes. If internet access allows weight download, swap the model with torchvision.models.resnet18(weights='DEFAULT') and replace the head to match num_classes.